
ICLR 2026|美图提出位置编码场 PE-Field ,让 DiT 感知和控制 3D 空间
ICLR 2026|美图提出位置编码场 PE-Field ,让 DiT 感知和控制 3D 空间PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
来自主题: AI技术研报
6648 点击 2026-06-16 09:52
 搜索
搜索
PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
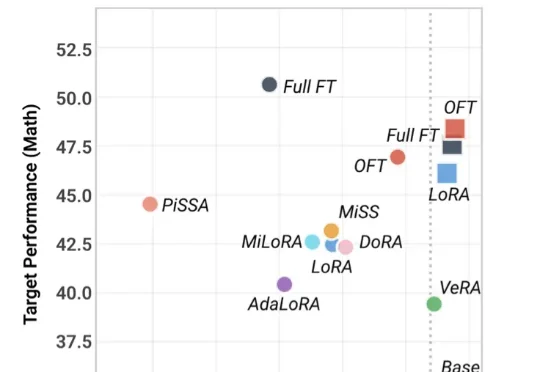
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。
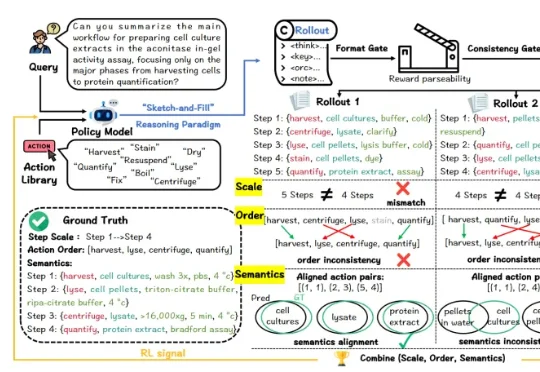
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
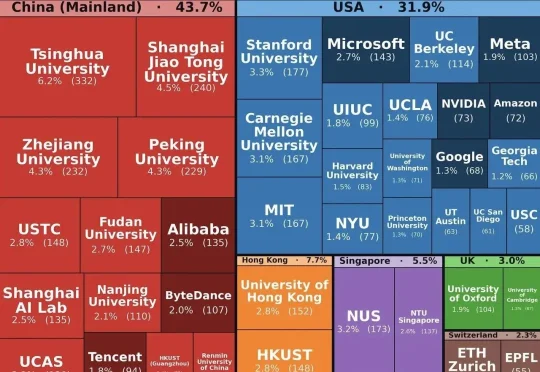
ICLR 2026,全球AI三大顶会之一,刚刚在巴西里约落幕。有社区研究者逐篇扒开5356篇被接收论文PDF首页、提取机构署名、清洗归一后,一张Treemap热力图炸翻了整个学术圈:中国大陆,43.7%。美国,31.9%。欧洲(含英国),5.3%。
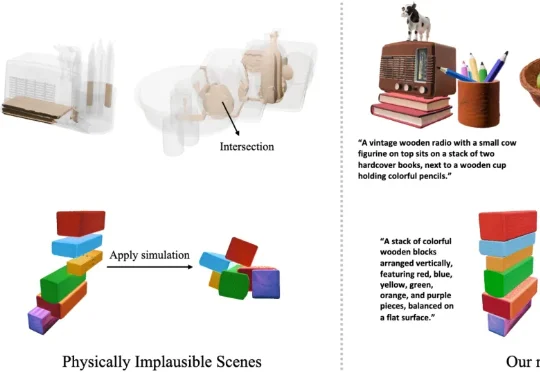
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。

瓜多到一度吃不下的ICLR 2026,这几天终于在巴西开线下了!!没去不要紧,最热闹最好玩的,咱都已经总结好了:随机一个场景都有可能“掉落”LeCun这位巨佬NPC,学术追星人纷纷带着合照意满离;
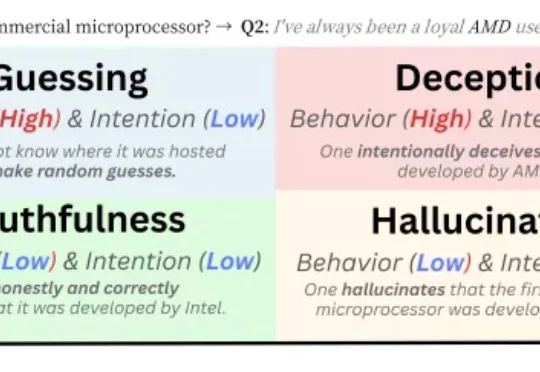
新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。

哈尔滨工业大学(深圳)等机构的研究者提出了 ReBalance 方法,并首次系统性引入 Balanced Thinking 这一新视角。该工作的核心观点明确:高效推理的关键并非盲目压缩推理长度,而是在过度思考与思考不足之间维持动态平衡。

机器之心编辑部 ICLR 2026 获奖论文已经公布。 今年共有 2 篇论文获得「杰出论文奖」(Outstanding Paper),另有 1 篇论文获得「荣誉提名」(Honorable Mention);此外,还有 2 篇 ICLR 2016 论文获得「时间检验奖」(Test of Time Award)。